MemCache是一个自由、源代码开放、高性能、分布式的分布内存对象缓存系统,用于动态Web应用以减轻数据库的负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站的访问速度
学习参考网址:http://www.csdn.net/article/2016-03-16/2826609
http://www.open-open.com/lib/view/open1384089806086.html
http://369369.blog.51cto.com/319630/833234
MemCache是一个自由、源代码开放、高性能、分布式的分布内存对象缓存系统,用于动态Web应用以减轻数据库的负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站的访问速度。
Memcache可以应对任意多个连接,使用非阻塞的网络IO。它的工作机制是在内存中开辟一块空间,然后建立一个HashTable,Memcached自管理这些HashTable。
MemCache是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)所使用的Key-value存储,数据可以来自于数据库调用、API调用、页面渲染的结果等。
MemCache和MemCached的区别:
MemCache是项目的名称
MenCached是MemCache服务器端可以执行文件的名称
首先,MemCached是以守护程序方式运行于一个或多个服务器中,随时接受客户端的连接操作,客户端可以由各种语言编写,目前已知的客户端API包括Perl/PHP/Python/Ruby/Java/C#/C 等。
客户端在与MemCached服务建立连接之后,接下来就是存取对象了,每个被存取的对象都有一个唯一的标识符key,存取操作均通过这些key进行。保存到memcached中的对象实际上是放置在内存中的,并不是保存在cache文件中的,这也是为什么Memcached能够如此高效快速的原因。注意,这些对象并不是持久的,服务停止后,里面的数据就会丢失。
与许多cache工具类似,MemCached的原理并不复杂。它采用了C/S的模式,在server端启动服务进程,在启动时可以指定监听的ip,自己的端口号,所使用的内存大小等几个关键参数。MemCached的目前版本是通过C实现 ,采用了单进程、单线程、异步IO、基于事件(event_based)的服务方式,使用libevent(Libevent 是一个用C语言编写的、轻量级的开源高性能网络库)作为事件通知实现。多个server可以协同工作,但这些server之间没有任何通讯联系,每个server只对自己的数据进行管理。
需要缓存的对象或数据是以key-value对的形式保存在server端的。key的值通过hash进行转换,根据hash值把value传递到对应的具体某个server上。当需要获取对象数据时,也根据key进行。首先对key进行hash,通过获得的值可以确定它被保存到哪台server上,然后再向该server发出请求。client端只需要知道保存hash(key)的值在哪台服务器上就可以了。
简单说,MemCache的工作就是在专门的机器内存里维护一张巨大的hash表,来存储经常被读写的一些数组与文件,从而极大地提高网站的运行效率。
操作流程: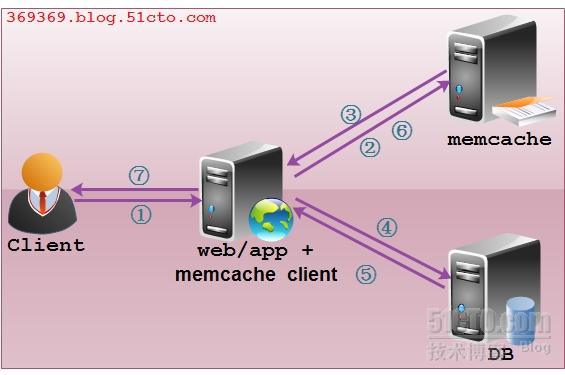
- 检查客户端的请求数据是否在Memcached中,如有,直接把请求数据返回,不再对数据库进行任何操作,操作路径为:1->2->3->7
- 如果请求的数据不在Memcached中,就去查询数据库,把从数据库中获取的数据返回给客户端,同时把数据缓存一份到memcached中(memcached客户端不负责,需要程序明确实现),操作路径为:1->2->4->5->7->6
- 每次更新数据库的同时更新memcached中的数据,保持一致性
- 当分配给memcached的内存空间用完之后,会使用LRU(Least Recently Used,最近最少使用)策略加上到期失效策略,失效数据首先被替换,然后再替换最近未使用的数据。
Memcached特征:
- 协议简单:它是基于文本行的协议,直接通过Telnet在memcached服务器上可进行存取数据操作
- 基于libevent:Libevent 是一个用C语言编写的、轻量级的开源高性能网络库
- 内置的内存管理方式:所有数据都保存在内存中,存取数据比硬盘快。当内存满后,通过LRU算法自动删除不使用的缓存,但是没有考虑数据的容灾问题,重启服务后,所有数据会丢失。
- 分布式:各个memcached服务器之间互不通信,各自独立存取数据,不共享任何信息。服务器并不具备分布式功能。分布式部署取决于memcache客户端。
MemCache访问模型: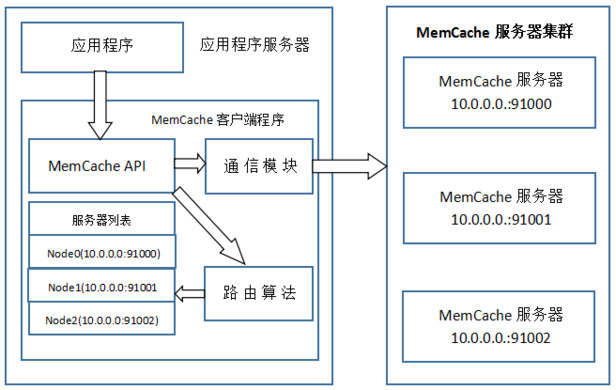
基于上图,梳理一下MemCache一次写缓存的流程:
- 应用程序输入需要写缓存的数据
- API将key输入路由算法模块,路由算法根据key和MemCache集群服务器列表得到一台服务器编号
- 由服务器编号得到MemCache及其IP地址和端口号
- API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作
从上图可以看出,在对服务器集群的管理中,路由算法至关重要。
余数hash算法:
先求得键的整数散列值,再除以服务器台数,根据余数确定存取服务器。
由于hashcode随机性比较强,所以使用余数hash路由算法可以保证缓存数据在整个MemCache服务集群中有比较均衡的分布。但是当分布式服务集群需要扩容的时候,即MemCache服务器增加(或减少)的时候,会造成大量数据无法正确命中,而且那些大量的无法命中的数据还在原缓存中在被移除前占据着内存。这就没有达到减轻数据库负载能力的目的。一致性hash算法:
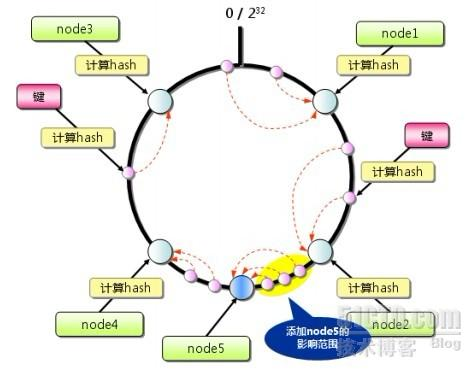
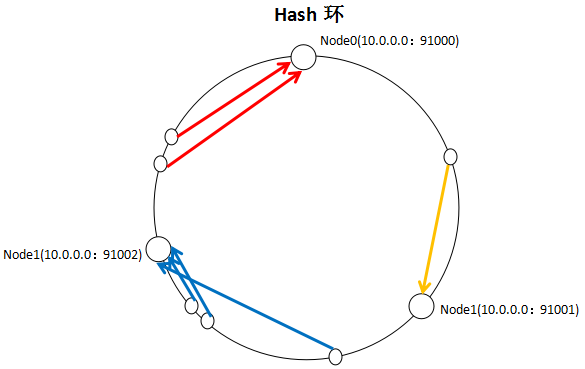
一致性hash算法通过一个叫做一致性Hash环的数据结构实现key到缓存服务器的Hash映射。
具体算法过程:
先构造出一个长度为2的32次方的整数环(即一致性Hash环),根据节点名称的Hash值将缓存服务器节点放置在这个环上,然后根据需要缓存的数据的key值计算得到其hash值,然后在Hash环上顺时针查找 距离这个key值的hash值 最近的服务器节点,完成key到服务器的映射查找。
如果添加了一台MemCache服务器,只在环上增加服务器的逆时针方向的第一台服务器上的键会受到影响。
MemCache内存分配: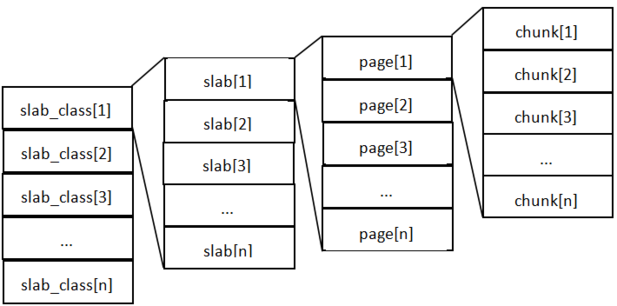
- Memcache将内存空间分为一组slab
- 每个slab下又有若干个page,每个page默认是1M。如果一个slab占用100M内存的话,那么这个slab下应该有100个page
- 每个page里包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的。
- 有相同大小的chunk的slab被组织在一起,称为slab_class
MemCache内存分配的方式称为allocator,slab的数量是有限的,几个,几十个或者几百个,这个和启动参数的配置有关。
MemCache中的value存放的地方是由value的大小决定的,value总是会被存放到与chunk大小最接近的一个slab中。放slab的时候,首先slab要申请内存,申请内存是以page为单位的,所以在放入第一个数据的时候,无论大小为多少,都会有一个1M大小的page会分配给slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了chunk数组,最后从这个chunk数组中 选择一个用于储存数据。
如果这个slab中没有chunk可以分配的话,那么MemCache会把这个slab中最近最少使用的chunk中的数据清理掉,然后放上最新的数据。
总结:
- MemCache的内存分配chunk里面会有内存浪费,88字节的value分配在128字节的chunk中就损失了30字节,但是这也避免了管理内存碎片的问题
- MemCache的LRU算法不是针对全局的,是针对slab的
- MemCache存放的value大小是有限制的,因为一个新数据过来,slab会先以page为单位申请一块内存,申请的内存最多只有1M,所以value的大小不能超过1M
MemCache的特性和限制:
- MemCache中可以保存的item数据量是没有限制的,只有内存足够
- MemCache单进程在32位机器中最大使用内存为2G,64位上则没有限制
- key最大为250个字节,超过该长度无法存储
- 单个item最大数据是1M,超过1M的数据不予存储
- MemCache服务端是不安全的,比如已知某个MemCache节点,可以直接Telnet过去,并通过flush_all让已经存在的键值对失效
- 不能够遍历MemCache中的所以item,因为此操作的速度相对缓慢而且会阻塞其他的操作
- MemCache的高性能源自于两端哈希结构:第一段在客户端,通过Hash算法根据key值算出一个节点;第二段在服务器端,通过一个内部的Hash算法,找到真正的item并返回给客户端。从实现的角度看,MemCache是一个非阻塞式的、基于事件的服务器程序。
- MemCache设置添加某个key值的时候,传入expiry为0表示这个key值永久有效,但这个key值也会在30天后失效,这个失效时间在MemCache源码里规定的,开发者无法改变。
代码直接拿来的,没有测试。。。
网址
1 | public class MemCacheManager |